|
Владимир Мистюков, Павел Володин, Владимир Капитанов
Однокристальная реализация алгоритма БПФ на ПЛИС фирмы Xilinx
Рассматриваются предпосылки и методика однокристальной реализации быстрого преобразования Фурье на приборах программируемой логики фирмы Xilinx. Приводятся реальные показатели по быстродействию и занимаемому объему модулей, созданных на ряде инструментальных средств отечественного производства.
В настоящее время очень актуальна задача быстрой обработки больших массивов данных, что влечет за собой значительное увеличение производительности обрабатывающих устройств. В связи с этим в последнее время развивается тенденция реализации высокоскоростных устройств цифровой обработки сигналов (ЦОС) на программируемых логических схемах (ПЛИС). ПЛИС типа FPGA (Field Programmable Gate Array) фирмы Xilinx идеально подходят для решения задач потоковой обработки данных с достаточно регулярной структурой алгоритма, что как раз и характерно для задач ЦОС. При этом за счет возможности аппаратного распараллеливания процесса обработки, гибкой адаптации структуры устройства под алгоритм, высокой эффективности интегрированных средств разработки достаточно просто построить в кратчайшие сроки высокопроизводительную систему ЦОС на одном кристалле. Поэтому область применения ПЛИС Xilinx практически безгранична: это телекоммуникации и сетевые решения, видеообработка, промышленное оборудование, измерительная и медицинская техника, а также специальная аппаратура.
Предпосылки использования ПЛИС для высокопроизводительной цифровой обработки
Конечно, существует ряд альтернативных решений построения высокопроизводительных систем, в частности на заказных интегральных схемах (ASIC) и специализированных процессорах цифровой обработки сигналов (DSP). Рассмотрения вопроса реализации системы с использованием ASIC в данной статье мы касаться не будем, поскольку данный подход окупает себя только при достаточно крупносерийном производстве и в условиях отечественного рынка совершенно неприемлем. В то же время производительности большинства современных DSP, как правило, не хватает для однокристальной реализации алгоритма и, как следствие, возникает необходимость построения многопроцессорных систем на базе однокристальных цифровых процессоров обработки сигналов с присущей сложностью сопряжения нескольких процессоров и отладкой их функционирования в реальном масштабе времени. Да и стоимость конечной реализации подобной системы оставляет желать лучшего.
Произведем сравнительную оценку производительности универсального процессора, процессоров ЦОС и ПЛИС Xilinx с использованием подсчета только числа базовых операций ЦОС — умножения с накоплением в секунду MAC (Multiply-Accumulate). На рис. 1 приведены характеристики по производительности универсального процессора Pentium II (450 МГц), процессоров ЦОС TMS320C5416 (160 МГц), TMS320C6701 (167 МГц) и AD21062 (40 МГц), ПЛИС Xilinx XCV100-4 (серия Virtex, 100 тыс. вентилей) и XCV400-4 (серия Virtex, 400 тыс. вентилей) при выполнении МАС 8-, 16- и 32-битных операндов с фиксированной точкой.
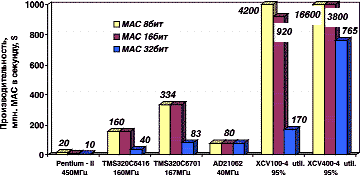
Рис. 1. Сравнительные характеристики различных аппаратных средств по производительности
Производительность ПЛИС Xilinx на задачах ЦОС тем выше, чем более высокая параллельность обработки используется в алгоритме, что ведет за собой соответствующее увеличение объема логики на кристалле. Однако достаточно малый кристалл ПЛИС Xilinx XCV100 (стоимость которого — около 90$) на 8-битных операциях обеспечивает производительность, почти на порядок превосходящую показатели мощного ЦОС- процессора. Это обусловлено распараллеливанием самого процесса обработки и эффективным использованием архитектурных особенностей ПЛИС, причем, что особенно важно, за счет высокой скорости межкристального обмена ПЛИС возможен многоканальный ввод/вывод данных на предельных частотах, вплоть до 200 МГц.
Конечно, было бы некорректным проводить анализ сравнительной производительности реализации алгоритмов ЦОС без учета их стоимости. На рис. 2 приведена удельная стоимость 1 млн МАС в секунду для ранее рассмотренных устройств, и, как видно, ПЛИС обеспечивают беспрецедентно низкие стоимостные затраты при значительном выигрыше в производительности.
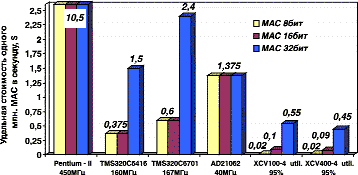
Рис. 2. Стоимость 1 млн МАС в секунду для разлиных аппаратных средств
Для реализации высокоскоростных устройств ЦОС наиболее приемлемы ПЛИС таких семейств, как Virtex, Virtex-E, а также XC4000XL/XLA/XV и Spartan/XL, основные характеристики которых по сериям приведены в табл. 1 [1, 2].
Таблица 1. Основные характеристики ПЛИС Xilinx серий Virtex, Virtex-e, XC4000XL/XLAXV, Spartan/XL
| Семейство ПЛИС |
Системная частота, МГц |
Быстродействие, нс/вентиль |
Скорость обмена chip-to-chip, МГц |
Емкость ПЛИС, системных вентилей |
| Virtex |
до 200 |
0,6 |
до 200 HSTL 4) |
до 1000 тыс. |
| Virtex-E |
до 250 |
0,5 |
до 622 (LVDS) |
до 3200 тыс. |
| XC4000XL/XLA/XV |
до 130 |
0,7 |
более 100 |
до 500 тыс. |
| Spartan/XL |
до 100 |
0,8 |
более 80 |
до 40 тыс. |
Привлекательной чертой ПЛИС Xilinx для реализации алгоритмов ЦОС по сравнению с ПЛИС других фирм является наличие внутреннего быстродействующего (до 250 МГц для Virtex-Е, до 133 МГц для XC4000X) распределенного ОЗУ, объединяемого в блоки требуемого размера. Использование данного ОЗУ очень эффективно для реализации алгоритмов ЦОС методом распределенной арифметики, а также для хранения коэффициентов, результатов промежуточных вычислений и т. п. [3, 4].
Достаточно хорошо используется распределенное ОЗУ Xilinx при реализации алгоритма быстрого преобразования Фурье.
Однокристальная реализация на ПЛИС алгоритма быстрого преобразования Фурье
Задача выполнения БПФ за минимальное время является довольно актуальной при построении быстродействующих систем спектрального анализа задач обнаружения, цифровой фильтрации в частотной области и т. д.
В настоящее время существует достаточно много реализаций алгоритма БПФ на заказных СБИС и процессорах ЦОС, однако реализация алгоритма на ПЛИС позволяет создать наиболее оптимальные архитектурные решения с максимальной производительностью для современного технологического уровня СБИС.
Вычисление прямого ДПФ в общем случае производится по следующему выражению [5]:
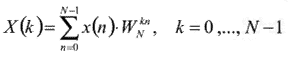 |
, (1) |
где x(n) — последовательность из N временных отсчетов;
X(k) — последовательность из N частотных отсчетов;
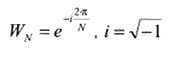
Вычисление непосредственно по формуле (1) требует весьма большого числа операций: примерно N2 операций умножения и N2 операций сложения комплексных чисел. Алгоритмы БПФ позволяют значительно сократить их число.
Рассмотрим алгоритм быстрого преобразования Фурье с прореживанием по времени. Если последовательность x(n) длиной N = 2L, где L? > 0, L — целое, разделить на две N/2 — точечные последовательности, состоящие из x(n) с четными и нечетными номерами соответственно, то выражение для ДПФ можно записать в виде:
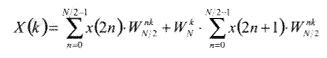
k = 0,..., N - 1, |
, (2) |
где x(n) — последовательность из N временных отсчетов;
X(k) — последовательность из N частотных отсчетов;
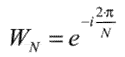 — коэффициенты преобразования, — коэффициенты преобразования,
где 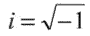 . .
Каждая из сумм в (2) является N/2-точечным ДПФ, которое аналогичным образом можно представить через N/4-точечные, N/4- точечные через N/8-точечные и т. д., пока не останутся только 2-точечные. Таких ступеней преобразования всего будет L = log2 N. На m-ступени происходит преобразование множества N комплексных чисел Xm(n) в множество N комплексных чисел Xm+1(n) в соответствии с базовой операцией «бабочка», описываемой выражениями:
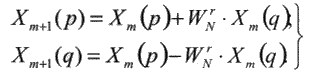 |
, (3) |
На рис. 3 изображен направленный граф, реализующий алгоритм БПФ для N = 8 с прореживанием по времени [5].
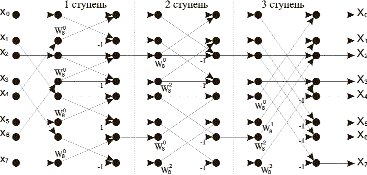
Рис. 3. Алгоритм БПФ 8 точек с прореживанием по времени
Процесс вычисления полного преобразования можно условно разбить на три шага. На первом происходит преобразование входной последовательности xn в соответствии с двоичной инверсией номеров и последующим вычислением первого частичного преобразования согласно выражению (3). На втором происходит вычисление второго частичного преобразования, на третьем — полного преобразования Xn. Аналогично для вычисления БПФ 256 точек потребуется 8 шагов, 1024 точки — 10 шагов. Следует заметить, что подобным образом можно представить БПФ для любого N = 2L, где L? > 0, L — целое и равно числу шагов.
Оценим требуемую производительность устройства обработки. Для вычисления БПФ 256 точек по основанию 2 с комплексными входными данными требуется примерно 3 тыс. умножений действительных операндов и 5,5 тыс. сложений действительных операндов, для 1024 — точечного БПФ по основанию 2 — примерно 16 тыс. умножений и 28,5 тыс. сложений [5]. Оценку проведем с помощью следующего выражения:
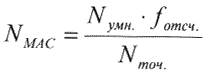 |
, (4) |
где NMAC — число операций типа умножения-накопления, c-1;
Nумн. — число умножений, необходимых для вычисления преобразования;
fотсч. — частота поступления входных данных, Гц;
Nумн. — размер преобразования.
Таким образом, при частоте поступления входных данных 40 МГц производительность устройства вычисления БПФ 256 точек должна составлять не менее 460 млн МАС в секунду, устройства вычисления БПФ 1024 точки — не менее 620 млн МАС в секунду.
На рис. 4 представлена структурная схема устройства, реализующего алгоритм БПФ на ПЛИС. Рассмотрим назначение каждого блока. Входное ОЗУ используется для загрузки исходной последовательности, хранения результатов промежуточных вычислений и выгрузки результатов преобразования. Буферное ОЗУ нужно только для хранения результатов промежуточных вычислений, в ПЗУ хранятся значения коэффициентов WNr. Применение двух банков ОЗУ позволяет совместить операции чтения и записи, а также обеспечить корректность обработки данных. Блок «бабочка» выполняет вычислительные действия согласно выражению (3), причем число умножителей в общем случае может быть различным — от 1 до 4. Блок управления отвечает за общую синхронизацию схемы и выдачу необходимых сигналов управления.
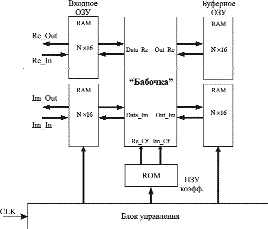
Рис. 4. Обобщенная структурная схема БПФ на ПЛИС Xilinx
Если вычисление преобразования согласно алгоритму БПФ при N = 256 происходит за 8 ступеней, то при аппаратной реализации на ПЛИС требуется добавить еще 2 ступени — ступень загрузки исходных данных и ступень выгрузки результатов преобразования. Таким образом, полное преобразование требует 10 ступепей:
1 ступень — запись входной последовательности во входное ОЗУ в соответствии с двоичной инверсией номеров.
2 ступень — первая ступень преобразования. Данные считываются из входного ОЗУ, преобразуются и записываются в буферное ОЗУ.
3 ступень — вторая ступень преобразования. Данные считываются из буферного ОЗУ, преобразуются и записываются во входное ОЗУ.
4, 6, 8 ступени аналогичны второй ступени.
5, 7, 9 ступени аналогичны третьей ступени.
10 ступень — выгрузка полученного преобразования из входного ОЗУ.
Приведенная на рис. 4 структурная схема с двумя умножителями «бабочки» реализована в виде функционально законченных модулей БПФ 256 и 1024 точки и разрядностью входных данных и коэффициентов 16 бит для ПЛИС фирмы Xilinx серий Virtex и XC4000XL/XLA/XV. Полученные качественные и количественные характеристики модулей приведены в табл. 2.
Таблица 2. Характеристики М-модулей БПФ на ПЛИС серии Virtex
| Размер преобразования |
Системных вентилей, тыс. |
Частота поступления входных данных, МГц-real-time |
Время преобразования, мкс |
Временная группа ПЛИС Virtex |
| 256 точек |
56 |
25,5 |
15 |
-6 |
| 256 точек* |
39 |
25,5 |
15 |
-6 |
| 1024 точки** |
51 |
19,5 |
72 |
-6 |
Данные модули БПФ, в дальнейшем М-модули (Макро-модули), поставляемые в качестве дополнительной библиотеки для системы проектирования Foundation фирмы Xilinx, могут легко быть добавлены в создаваемый пользователем проект с сохранением качественных и количественных характеристик модуля. Подобная независимость параметров модуля от окружающей пользовательской логики обусловлена использованием специальной методики топологического размещения, благодаря чему все модули являются линейно ориентированными макросами (RPM), а также использованием временных ограничений задержек распространения сигналов по кристаллу (атрибута TIMESPEC) [6].
На рис. 5 показана топология модуля БПФ 256 точек с внутренним ОЗУ в окне редактора Floorplanner пакета Foundation 2.1i фирмы Xilinx.
Рис. 5. Топология модуля БПФ 256 точек с внутренним ОЗУ
Рассмотренные М-модули БПФ оперируют с 16-разрядными входными данными и коэффициентами преобразования. Однако реальная разрядность поступающих данных для некоторых высокоскоростных приложений ограничивается 12, а иногда и 8 битами, что влечет за собой значительное сокращение объема модуля БПФ и соответствующий рост производительности. Поставляемые модули допускают оперативную модификацию под необходимую разрядность и размер преобразования.
В табл. 3 приведены параметры некоторых ПЛИС Xilinx семейств Virtex/Virtex-E и XC4000X, допускающих однокристальную реализацию разработанных модулей.
Таблица 3. Основные характеристики ПЛИС серий Virtex и XC4000
| ПЛИС Xilinx (выборочно) |
Серия XC4000 |
Серия Virtex/Virtex-E |
| XC4062XLA |
XC4085XLA |
XCV400 |
XCV1000 |
XVC1600E |
| Системных вентилей, тыс. |
130 |
180 |
468 |
1124 |
2188 |
| Количество логических ячеек* |
5472 |
7448 |
10800 |
27648 |
34992 |
| Макс. размер внутреннего распределенного ОЗУ, бит** |
40,5 |
98 |
150 |
384 |
486 |
| Макс. размер внутреннего блочного ОЗУ, Кбит |
нет |
нет |
32 |
128 |
576 |
| Макс. число портов ввода/вывода |
384 |
448 |
404 |
514 |
724 |
Примечание:
* - одна логическая ячейка содержит 4-входовую LUT-таблицу и триггер.
** - случай использования всех логических ресурсов в качестве ОЗУ.
Из сопоставления данных табл. 2 и табл. 3 видно, что после реализации модуля БПФ на рассмотренных кристаллах остаются значительные свободные вентильные ресурсы, которые можно использовать для создания в той же ПЛИС дополнительных устройств пользователя, например, встроенного контроллера шины PCI и логики сопряжения с аналого-цифровым преобразователем (рис. 6).

Рис. 6. Интегрированный подход к реализации устройства цифровой обработки на ПЛИС Xilinx
Продолжение следует...
capt@scan.voronezh.su
http://www.xilinx.ru
|


